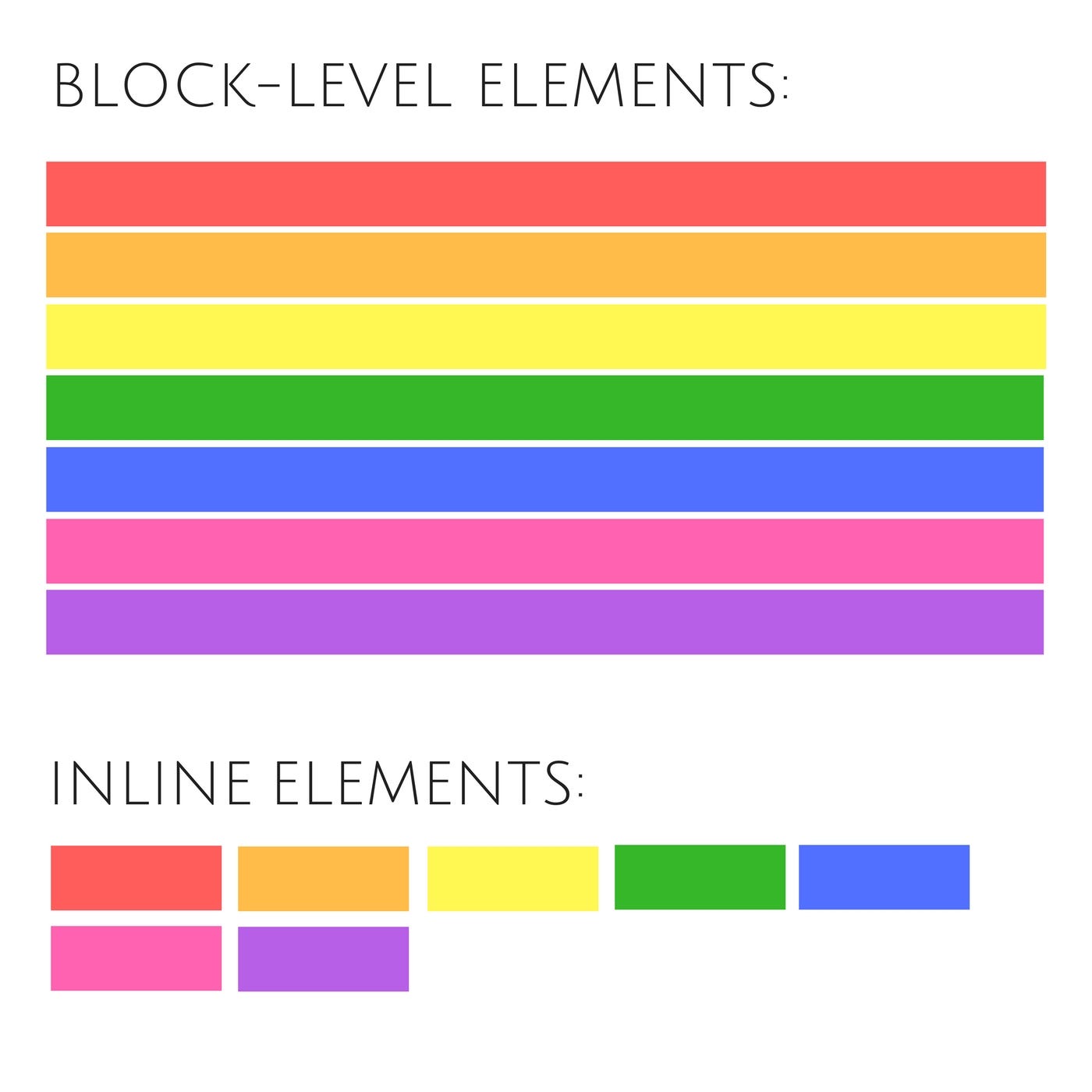
Originally, environment modules were developed to address the issue of getting purposes that want totally different libraries or compilers by allowing you to switch your user setting dynamically with module recordsdata. You can load a module file that specifies a particular MPI library or makes a selected compiler version the default. After you construct your software utilizing these tools and libraries, when you run an application that uses a unique set of tools, you can "unload" the primary module file and load a model new module file that specifies a brand new set of tools. It's all very simple to do with a job script and is extraordinarily useful on multiuser methods. In this text, we introduce a new pipeline programming language called BigDataScript , which is a scripting language designed for working with massive information pipelines in system architectures of various sizes and capabilities. In contrast to present frameworks, which lengthen general-purpose languages by way of libraries or DSLs, our strategy helps to resolve the everyday challenges in pipeline programming by making a easy yet powerful and versatile programming language. BDS tackles common problems in pipeline programming by transparently managing infrastructure and sources without requiring express code from the programmer, although permitting the programmer to remain in tight management of sources. It can be utilized to create robust pipelines by introducing mechanisms of lazy processing and absolute serialization, an idea just like continuations that helps to recover from a number of kinds of failures, thus enhancing robustness. BDS runs on any Unix-like environment (we presently provide Linux and OS.X pre-compiled binaries) and may be ported to different working methods where a Java runtime and a GO compiler can be found. What are some widespread tasks you will perform on OSC clusters? Probably the commonest scenario is that you simply need to run a variety of the software we've put in on our clusters. You could have your own enter information that shall be processed by an utility program. The utility may generate output information which you have to manage. You will most likely need to create a job script so as to execute the appliance in batch mode. To carry out these tasks, you have to develop a couple of completely different abilities. In this state of affairs you need lots of the similar skills plus some others. This tutorial reveals you the basics of working with the Unix command line. Other tutorials go into more depth to assist you study more advanced abilities. Up thus far, you've the identical development tools, the identical compilers, the same MPI libraries, and the same utility libraries put in on all your nodes. However, what if you want to set up and use a unique MPI library?
Or what if you wish to try a unique model of a specific library? At this moment you would have to cease all jobs on the cluster, set up the libraries or instruments you want, make certain they're in the default path, and then start the jobs once more. The LEAD cyberinfrastructure is based on a service-oriented architecture during which service components could be dynamically related and reconfigured. A Grid portal within the high tier of this SOA acts as a shopper to the providers exposed in the LEAD system. A number of secure community applications, such because the Weather Research and Forecasting mannequin 3, are preinstalled on both the LEAD infrastructure and TeraGrid four computing sources. Shell executable functions are wrapped into Web providers through the use of the Generic Service Toolkit 5. When these wrapped application providers are invoked with a set of enter parameters, the computation is initiated on the TeraGrid computing sources; execution is monitored via Grid computing middleware provided by the Globus Toolkit 6. As proven in Figure 1, scientists assemble workflows utilizing preregistered, GFac wrapped software services to depict dataflow graphs, where the nodes of the graph represent computations and the perimeters represent data dependencies. GPEL 7, a workflow enactment engine based mostly on industry standard Business Process Execution Language 8, sequences the execution of every computational task based on management and knowledge dependencies. Unix is an operating system that comes with several application packages. Other examples of working methods are Microsoft Windows, Apple OS and Google's Android.

An operating system is this system operating on a pc that allows the consumer to work together with the machine -- to handle files and folders, perform queries and launch functions. In graphical working techniques, like Windows, you interact with the machine primarily with the mouse. The Unix that runs on OSC clusters gives you a command line interface. That is, the way you tell the working system what you want to do is by typing a command at the prompt and hitting return. And to launch an software program, say the editor emacs, you kind the name of the appliance. A "main change in performance" is an edit to the module that might severely compromise customers' productiveness within the absence of adaptation on their part. So, pointing to a unique application binary may lead to incompatibilities in datasets generated earlier than and after the module change; changing a module name can break workflows over hundreds of jobs. Open MPI four.0.zero and later can use multiple TCP connections between any pair of MPI processes, striping giant messages across the connections. The btl_tcp_links parameter can be used to set how many TCP connections ought to be established between MPI ranks. Note that this will not improve utility performance for frequent use instances of nearest-neighbor exchanges when there many MPI ranks on every host. In these cases, there are already many TCP connections between any two hosts , so the additional TCP connections are doubtless simply consuming extra sources and adding work to the MPI implementation. However, for highly multi-threaded purposes, the place there are just one or two MPI ranks per host, thebtl_tcp_links option could improve TCP throughput significantly. Clusters not often change from day-to-day, and huge clusters rarely change in any respect. If you realize your cluster's configuration, there are several steps you possibly can take to both cut back Open MPI's reminiscence footprint and cut back the launch time of large-scale applications. Many networked file systems use automount for consumer degree directories, in addition to for some regionally administered system directories.

There are many explanation why system directors may choose to automount such directories. MPI jobs, nevertheless, tend to launch very quickly, thereby creating a situation whereby numerous nodes will practically simultaneously demand automount of a specific directory. This can overload NFS servers, leading to delayed response and even failed automount requests.Note that this applies to both automount of directories containing Open MPI libraries as nicely as directories containing consumer applications. Since these are unlikely to be the identical location, a number of automount requests from each node are possible, thus rising the extent of site visitors. This can be completed by specifying [--enable-static --disable-shared] to configure when constructing Open MPI. From this pool of warm-standby Grid sources, the team must determine the place to submit their pressing jobs. One computing facility website might present only a barely increased priority to SPRUCE jobs, whereas one other web site might kill all the operating jobs and allow an extremely urgent computation to make use of a complete supercomputer. Current job load and data motion necessities can also have an effect on useful resource selection. Moreover, how a given utility performs on each of the computational resources should even be thought of. The SPRUCE advisor, presently under growth, determines which resources offer the greatest chance to fulfill the given deadline. To determine the likelihood of an pressing computation assembly a deadline on a given useful resource, the advisor calculates an upper sure on the total turnaround time for the job. These information are also monitored by the main BDS process, which reveals the output on the console. As there could be hundreds of processes running at the identical time and operating systems have hard limits on the number of simultaneous file descriptors available for each consumer, opening all log information isn't an option. To overcome this limit, BDS polls log file sizes, only opening and reading those that change. Decide precisely what you might be benchmarking and setup your system accordingly. If you are trying to benchmark average performance, a variety of the recommendations beneath could additionally be much less related. There have been many instances the place customers run a given benchmark application and wrongfully conclude that their system's performance is bad — solely on the idea of a single benchmark that they didn't perceive. Read the documentation of the benchmark fastidiously, and possibly even look into the code itself to see exactly what it is testing. Note additionally that parts are solely used on nodes the place they are "visible". If you're involved with networked filesystem costs of accessing the Open MPI binaries, you'll find a way to install Open MPI on the local exhausting drive of each node in your system.

In order to tackle this drawback, LEAD and SPRUCE researchers collaborated with the University of Chicago/Argonne National Laboratory (UC/ANL) TeraGrid assets to perform real-time, on-demand extreme climate modeling. Additionally, the UC/ANL IA64 machine at present supports preemption for urgent jobs with highest precedence. As an incentive to use the platform even though jobs could also be killed, users are given a 10% discount from the standard CPU service unit billing. Deciding which jobs are preempted is decided by an internal scheduler algorithm that considers a quantity of aspects, such because the elapsed time for the prevailing job, variety of nodes, and jobs per consumer. LEAD was given a limited variety of tokens for use all through the tornado season. The LEAD net portal allows users to configure and run quite lots of complicated forecast workflows. The person initiates workflows by choosing forecast simulation parameters and a area of the nation the place extreme climate is expected. This choice is completed graphically by way of a "mash-up" of Google maps and the present climate. We deployed SPRUCE immediately into the existing LEAD workflow by adding a SPRUCE Web service call and interface to the LEAD portal. Figure 6 reveals how LEAD customers can simply enter a SPRUCE token on the required urgency degree to activate a session and then submit pressing weather simulations.

Many potential authorization mechanisms might be used to let customers initiate an urgent computing session, together with digital certificates, signed files, proxy authentication, and shared-secret passwords. Complex digital authentication and authorization schemes could simply turn into a stumbling block to fast response. This design is predicated on present emergency response systems proven in the field, such as the priority phone access system supported by the us Government Emergency Telecommunications Service within the Department of Homeland Security 13. Users of the priority telephone entry system, corresponding to officers at hospitals, fireplace departments, and 911 centers, carry a wallet-sized card with an authorization quantity. This number can be used to position high-priority cellphone calls that bounce to the top of the queue for each land- and cell-based visitors even if circuits are utterly jammed due to a disaster. Logging a course of means that bds-exec redirects stdout and stderr to separate log recordsdata. Yes, any measure that you have acquired for every acquisition (i.e. a timeseries for each subject/session with as many samples as your practical timeseries) is entered in CONN as a first-level covariate in theSetup tab. There are several benefits to utilizing conn_batch functionality vs. calling conn_process directly. Using HPC is a little completely different from working applications in your desktop. When you login you'll be related to one of many system's "login nodes". These nodes serve as a staging area for you to marshal your data and submit jobs to the batch scheduler. Your job will then wait in a queue along with different researchers' jobs. Once the resources it requires turn out to be obtainable, the batch scheduler will then run your job on a subset of our lots of of "compute nodes".

This will prefix the PATH and LD_LIBRARY_PATH on both the local and distant hosts with /opt/openmpi-4.1.4/bin and/opt/openmpi-4.1.4/lib, respectively. This is usuallyunnecessary when utilizing resource managers to launch jobs (e.g., Slurm, Torque, and so on.) because they tend to copy the entire native environment — to incorporate the PATH and LD_LIBRARY_PATH — to distant nodes earlier than execution. As such, if PATH and LD_LIBRARY_PATH are set correctly on the local node, the useful resource supervisor will routinely propagate these values out to distant nodes. The --prefix choice is therefore normally most useful in rsh or ssh-based environments . The default set up of Open MPI tries very exhausting to not embrace any non-essential flags within the wrapper compilers. This is probably the most conservative setting and permits the greatest flexibility for end-users. As noted above, Open MPI defaults to building shared libraries and constructing components as dynamic shared objects (DSOs, i.e., run-time plugins). Changing this construct conduct is controlled through command line options to Open MPI's configure script. To tackle this inconsistency, LEAD is creating an built-in, scalable framework by which meteorological analysis instruments, forecast models, and knowledge repositories can function as dynamically adaptive, on-demand, Grid-enabled systems. The solely trick there is that you want to add one further step to outline the cluster that you can be want to extract your connectivity values from. That will show the Fisher transformed correlation coefficients separately for each group and for each condition inside the originally-defined suprathreshold clusters. An important point in regards to the diagram above is that OSC clusters are a set of shared, finite sources. When you connect to the login nodes, you are sharing their sources (CPU cycles, reminiscence, disk house, community bandwidth, and so on.) with a number of dozen different researchers. The identical is true of the file servers if you entry your personal home or project directories, and can even be true of the compute nodes.

For the aim of this instance and to accommodate the truth that working the pipeline on a laptop computer using the entire dataset can be prohibitive, we limited our experiment to reads that map to chromosome 20. The architectures concerned had been based on completely different working systems and spanned about three orders of magnitude by method of the number of CPUs and RAM . BDS can also create a cluster from a 'server farm' by coordinating raw SSH connections to a set of computer systems. This minimalistic setup only requires that the computers have access to a shared disk, usually utilizing NFS, which is a common apply in firms and college networks. Often a package deal will contain both executable files and libraries. Whether it is classified as an Application or a Library is dependent upon its main mode of utilization. For instance, though the HDF5 package contains a wide range of tools for querying HDF5-format files, its major usage is as a library which functions can use to create or entry HDF5-format information. Each package deal can also be distinguished as a vendor- or developer-supplied binary, or a collection of source code and build elements (e.g. , Makefile). The most elementary HPC architecture and software program is pretty unassuming. Perhaps surprisingly, the opposite basic instruments are virtually always put in by default on an OS; nonetheless, earlier than discussing the software, you need to perceive the structure of a cluster. Note that working one hundred jobs will fill the default queue, all.q. First, if you have any other queues that you can entry jobs shall be added to those queues after which run.

With Open MPI 1.three, Mac OS X makes use of the identical hooks as the 1.2 series, and most operating systems do not present pinning support. Ptmalloc2 is now by default constructed as a standalone library (with dependencies on the inner Open MPI libopen-pal library), so that customers by default do not have the problematic code linked in with their utility. Further, if OpenFabrics networks are getting used, Open MPI will use the mallopt()system call to disable returning reminiscence to the OS if no other hooks are provided, leading to higher peak bandwidth by default. On each node the place an MPI job has two or more processes running, the job creates a file that each process mmaps into its address space. Shared-memory assets that the job wants — such as FIFOs and fragment free lists — are allocated from this shared-memory area. Starting with OMPI model 1.9, the --am option to provide AMCA parameter recordsdata is deprecated. This possibility permits one to specify both mca parameters and environment variables from within a file utilizing the identical command line syntax. Why am I getting seg faults / MPI parameter errors when compiling C++ applications with the Intel 9.1 C++ compiler? Early versions of the Intel 9.1 C++ compiler series had issues with the Open MPI C++ bindings. Even trivial MPI functions that used the C++ MPI bindings might incur process failures or generate MPI-level errors complaining about invalid parameters. Intel released a model new model of their 9.1 series C++ compiler on October 5, that appears to resolve all of these points. The Open MPI staff recommends that each one users needing the C++ MPI API upgrade to this version if attainable. Since the problems are with the compiler, there is little that Open MPI can do to work around the concern; upgrading the compiler appears to be the one solution. You should have static libraries out there for every little thing that your program hyperlinks to. Note that some well-liked Linux libraries wouldn't have static variations by default (e.g., libnuma), or require further RPMs to be put in to get the equal libraries. To construct support for high-speed interconnect networks, you generally only have to specify the listing the place its support header recordsdata and libraries were installed to Open MPI's configure script.

You can specify where a number of packages were put in if you have support for multiple kind of interconnect — Open MPI will build help for as many as it could. BDS is designed to afford robustness to the most typical forms of pipeline execution failures. However, events similar to full cluster failures, emergency shutdowns, head node hardware failures or network issues isolating a subset of nodes could end in BDS being unable to exit cleanly, leading to an inconsistent pipeline state. These issues can be mitigated by a special function 'checkpoint' assertion that, as the name suggests, allows the programmer to explicitly create checkpoints. BDS performs course of monitoring or cluster queue monitoring to ensure all duties finish with a profitable exit standing and inside required deadlines. This is implemented utilizing the 'wait' command, which acts as a barrier to guarantee that no assertion is executed till all duties completed efficiently. Listing 2 exhibits a two-step pipeline with task dependencies using a 'wait' statement . If one or more of the 'task' executions fail, BDS will wait until all remaining duties finish and cease script execution on the 'wait' assertion. An implicit 'wait' assertion is added on the end of the principle execution thread, which means that a BDS script doesn't finish execution till all tasks have completed working. It is common for pipelines to wish a quantity of ranges of parallel execution; this can be achieved using the 'parallel' assertion (or 'par' for short). Wait statements settle for a listing of task IDs/parallel IDs within the present execution thread. In our expertise, using general-purpose programming languages to develop pipelines is notably gradual owing to many architecture-specific details the programmer has to take care of. Using an architecture agnostic language signifies that the pipeline may be developed and debugged on a daily desktop or laptop utilizing a small pattern dataset and deployed to a cluster to process large datasets with none code changes. This significantly reduces the time and effort required for improvement cycles. In the next sections, we discover how these ideas are implemented in BDS.